3.1. General Approach
Viskores is designed to provide a pervasive parallelism throughout all its visualization algorithms, meaning that the algorithm is designed to operate with independent concurrency at the finest possible level throughout. Viskores provides this pervasive parallelism by providing a programming construct called a worklet, which operates on a very fine granularity of data. The worklets are designed as serial components, and Viskores handles whatever layers of concurrency are necessary, thereby removing the onus from the visualization algorithm developer. Worklet operation is then wrapped into filter, which provide a simplified interface to end users.
A worklet is essentially a functor or kernel designed to operate on a small element of data. (The name “worklet” means work on a small amount of data.) The worklet is constrained to contain a serial and stateless function. These constraints form three critical purposes. First, the constraints on the worklets allow Viskores to schedule worklet invocations on a great many independent concurrent threads and thereby making the algorithm pervasively parallel. Second, the constraints allow Viskores to provide thread safety. By controlling the memory access the toolkit can insure that no worklet will have any memory collisions, false sharing, or other parallel programming pitfalls. Third, the constraints encourage good programming practices. The worklet model provides a natural approach to visualization algorithm design that also has good general performance characteristics.
Viskores allows developers to design algorithms that are run on massive amounts of threads. However, Viskores also allows developers to interface to applications, define data, and invoke algorithms that they have written or are provided otherwise. These two modes represent significantly different operations on the data. The operating code of an algorithm in a worklet is constrained to access only a small portion of data that is provided by the framework. Conversely, code that is building the data structures needs to manage the data in its entirety, but has little reason to perform computations on any particular element.
Consequently, Viskores is divided into two environments that handle each of these use cases. Each environment has its own API, and direct interaction between the environments is disallowed. The environments are as follows.
Execution Environment This is the environment in which the computational portion of algorithms are executed. The API for this environment provides work for one element with convenient access to information such as connectivity and neighborhood as needed by typical visualization algorithms. Code for the execution environment is designed to always execute on a very large number of threads.
Control Environment This is the environment that is used to interface with applications, interface with I/O devices, and schedule parallel execution of the algorithms. The associated API is designed for users that want to use Viskores to analyze their data using provided or supplied filters. Code for the control environment is designed to run on a single thread (or one single thread per process in an MPI job).
These dual programming environments are partially a convenience to isolate the application from the execution of the worklets and are partially a necessity to support GPU languages with host and device environments. The control and execution environments are logically equivalent to the host and device environments, respectively, in CUDA and other associated GPU languages.
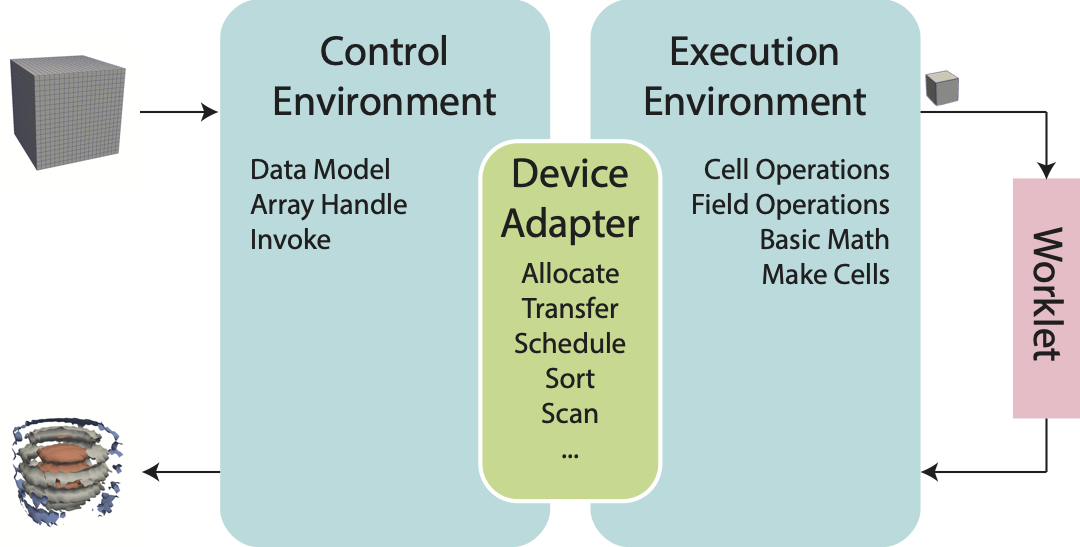
Figure 3.1 Diagram of the Viskores framework.
Figure 3.1 displays the relationship between the control and execution environment. The typical workflow when using Viskores is that first the control thread establishes a data set in the control environment and then invokes a parallel operation on the data using a filter. From there the data is logically divided into its constituent elements, which are sent to independent invocations of a worklet. The worklet invocations, being independent, are run on as many concurrent threads as are supported by the device. On completion the results of the worklet invocations are collected to a single data structure and a handle is returned back to the control environment.
Did You Know?
Are you only planning to use filters in Viskores that already exist? If so, then everything you work with will be in the control environment. The execution environment is only used when implementing algorithms for filters.
3.1.1. Package Structure
Viskores is organized in a hierarchy of nested packages. Viskores places definitions in namespaces that correspond to the package (with the exception that one package may specialize a template defined in a different namespace).
The base package is named viskores.
All classes within Viskores are placed either directly in the viskores package or in a package beneath it.
This helps prevent name collisions between Viskores and any other library.
As described at the beginning of this chapter, the Viskores API is divided into two distinct environments: the control environment and the execution environment.
The API for these two environments are located in the viskores::cont and viskoresexec packages, respectively.
Items located in the base viskores namespace are available in both environments.
Did You Know?
Although it is conventional to spell out names in identifiers (as outlined in https://github.com/Viskores/viskores/blob/master/docs/CodingConventions.md) there is an exception to abbreviate control and execution to cont and exec, respectively.
This is because it is also part of the coding convention to declare the entire namespace when using an identifier that is part of the corresponding package.
The shorter names make the identifiers easier to read, faster to type, and more feasible to pack lines in terminal displays.
These abbreviations are also used instead of more common abbreviations (e.g. ctrl for control) because, as part of actual English words, they are easier to type.
Further functionality in Viskores is built on top of the base viskores, viskores::cont, and viskores::exec packages.
Support classes for building worklets, introduced in Chapter Chapter 3.3 (Simple Worklets), are contained in the viskores::worklet package.
Other facilities in Viskores are provided in their own packages such as viskores::io, viskores::filter, and viskores::rendering.
These packages are described in Part 2 (Using Viskores).
Viskores contains code that uses specialized compiler features, such as those with CUDA, or libraries, such as Kokkos, that will not be available on all machines.
Code for these features are encapsulated in their own packages under the viskores::cont namespace: viskores::cont::cuda and viskores::cont::kokkos.
By convention all classes will be defined in a file with the same name as the class name (with a .h extension) located in a directory corresponding to the package name.
For example, the viskores::cont::DataSet class is found in the viskores/cont/DataSet.h header.
There are, however, exceptions to this rule.
Some smaller classes and types are grouped together for convenience.
These exceptions will be noted as necessary.
Within each namespace there may also be internal and detail sub-namespaces.
The internal namespaces contain features that are used internally and may change without notice.
The detail namespaces contain features that are used by a particular class but must be declared outside of that class.
Users should generally ignore classes in these namespaces.
3.1.2. Function and Method Environment Modifiers
Any function or method defined by Viskores must come with a modifier that determines in which environments the function may be run. These modifiers are C macros that Viskores uses to instruct the compiler for which architectures to compile each method. Most user code outside of Viskores need not use these macros with the important exception of any classes passed to Viskores. This occurs when defining new worklets, array storage, and device adapters.
Viskores provides three modifier macros, VISKORES_CONT, VISKORES_EXEC, and VISKORES_EXEC_CONT, which are used to declare functions and methods that can run in the control environment, execution environment, and both environments, respectively.
These macros get defined by including just about any Viskores header file, but including viskores/Types.h will ensure they are defined.
The modifier macro is placed after the template declaration, if there is one, and before the return type for the function. Here is a simple example of a function that will square a value. Since most types you would use this function on have operators in both the control and execution environments, the function is declared for both places.
1template<typename ValueType>
2VISKORES_EXEC_CONT ValueType Square(const ValueType& inValue)
3{
4 return inValue * inValue;
5}
The primary function of the modifier macros is to inject compiler-specific keywords that specify what architecture to compile code for.
For example, when compiling with CUDA, the control modifiers have __host__ in them and execution modifiers have __device__ in them.
It is sometimes the case that a function declared as VISKORES_EXEC_CONT has to call a method declared as VISKORES_EXEC or VISKORES_CONT.
Generally functions should not call other functions with incompatible control/execution modifiers, but sometimes a generic VISKORES_EXEC_CONT function calls another function determined by the template parameters, and the valid environments of this subfunction may be inconsistent.
For cases like this, you can use the VISKORES_SUPPRESS_EXEC_WARNINGS to tell the compiler to ignore the inconsistency when resolving the template.
When applied to a templated function or method, VISKORES_SUPPRESS_EXEC_WARNINGS is placed before the template keyword.
When applied to a non-templated method in a templated class, VISKORES_SUPPRESS_EXEC_WARNINGS is placed before the environment modifier macro.
1VISKORES_SUPPRESS_EXEC_WARNINGS
2template<typename Functor>
3VISKORES_EXEC_CONT void OverlyComplicatedForLoop(Functor& functor,
4 viskores::Id numInterations)
5{
6 for (viskores::Id index = 0; index < numInterations; index++)
7 {
8 functor();
9 }
10}